

One of the hardest parts of solving a reinforcement learning problem is to decide what problem you want to solve. But we can take heart from Herbert Simon who said
Solving a problem simply means representing it so as to make the solution transparent.
Although we want to use reinforcement learning to solve complex, real-world problems, a lot of important considerations can be illuminated by using well-known games as toy examples. In this spirit we’ll look at how to model the classic card game of cribbage as a reinforcement learning problem.
The Game of Cribbage
Cribbage can be played with two, three, or four players and while the basic game doesn’t change, a number of tactics and strategies do depend on the number of players. Our first modelling decision, then, is that we will consider only the basic two-player version of the game. Two-player cribbage sees the players play a number of hands with the goal of scoring 121 points before their opponent. This makes the hand the basic unit of game play. Every hand unfolds in three phases: throwing, pegging, and scoring.
The throwing phase starts with both players being dealt six cards from a single deck. The players each choose four cards from this initial hand to keep and two cards to throw into the crib, which belongs to the dealer. The non-dealer then cuts the deck and the top card becomes the starter card for the hand. Once these opening formalities are concluded the game proceeds in two phases.
For the pegging phase, players alternate playing cards from their hand into the count, with cards worth their face value. Points are scored for pairs and runs of sequential cards, or for making the count exactly 15 or 31. Once the count reaches 31, or if neither player can legally play, a new count is begun from 0.
For the scoring phase, players score their points for pairs, runs, 15s, and flushes with their hand and the starter card that was flipped up at the beginning of the hand. The dealer gets to score the crib in the same way, but the non-dealer counts their hand first. This order is important since the game ends immediately once either player reaches 121 points.
An important feature of cribbage is that it, like most card games, is a game of imperfect information. Although players have full information about their own hands and about cards that have been previously played, they are largely in the dark about which cards are held by their opponents. This contrasts with games like chess or go, where all of the factors influencing the game are equally known to all players.
The Parts of a Reinforcement Learning Problem
Now that we have an idea about the game of cribbage, we can get down to the nitty-gritty of reinforcement learning. What do we have to do be happy that we’ve properly modelled the game?
Any reinforcement learning problem is based on this classic diagram: the agent-environment loop. You’ll recognize this basic diagram from artificial intelligence, control theory, neuroscience, psychology, economics, you name it! At its heart, the diagram tells us that there is an agent who perceives its environment and whose actions can alter the environment. This agent might even come across some rewards along the way.

In order to model cribbage as a reinforcement learning problem, then, we should be able to describe:
- What is included in the state of the environment;
- What actions can be available to the agent; and
- What rewards might exist for the agent in the environment.
Modelling the Throwing Phase
We start by modelling the throwing phase of cribbage in reinforcement learning terms. This phase of the game occurs at the beginning of each hand, after each player has received 6 cards.
The Throwing Phase’s States
Although describing the state of the game at this point requires knowing all 12 cards that have been dealt, we will only ever be able to observe (and make decisions based on) the 6 cards in our hand. An additional consideration is which player dealt the hand, since they will earn the points that are in the crib for this hand. Since there two players, there are two possible dealers.
This means that there are $$2 \times \binom{52}{6} = 40,717,040$$ states for the throwing phase.
The Throwing Phase’s Actions
Both players choose 2 of their 6 cards to throw into the crib, whose points will be counted by the dealer at the end of the hand. Implicitly, this action also chooses which 4 cards a player will keep in their hand.
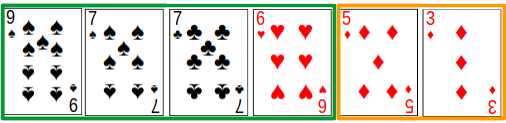
However we model the decision, there are $$\binom{6}{2} = \binom{6}{4} = 15$$ actions available to a player for every state in the throwing phase.
The Throwing Phase’s Rewards
Technically speaking, there are no rewards from the throwing phase because no points are scored. Although we could wait until the end of the game and propagate a win/loss reward signal across all decisions, this throws away the valuable information contained in these points scored, and which directly and wholly lead to victory. This is an important modelling consideration, since it avoids biasing our learning agents. In contrast, individual moves in chess can’t be evaluated solely based on the balance of material, since a number of other factors contribute to position value (and to an eventual win or loss).
Specifically, the decision of which cards to throw affects the points scored at the end of the hand (directly) as well as the points scored during the pegging phase (indirectly). We can capture this as a simple sum: $$R_{Throwing} = \begin{cases}R_{Pegging} + R_{Own Hand} + R_{Crib} &\text{if agent is the dealer}\\R_{Pegging} + R_{Own Hand} – R_{Crib} &\text{of opponent is the dealer}\end{cases}$$
Modelling the Pegging Phase
Next we model the pegging phase. This part of the game is a bit more involved than throwing cards into the crib, but it is also largely independent of the earlier phase. Starting with the player to the dealer’s left, which in the two-player game is simply the non-dealer, players play in turn onto the pile while keeping a common count of card values on the pile. Once the count reaches 31 (or no player can play without pushing the count above 31) a new pile begins.
The Pegging Phase’s States
The state of the game during the pegging phase consists of many factors. Considering only the cards in the game, our state is affected by the 12 cards that were originally dealt to the players as well as which of these cards were thrown in the crib, which of these cards have already been played, and which card was cut from the deck as the starter card.
As with the throwing phase, however, players only have partial information: they can only see cards in their hand or cards that have already been played. What’s more, the number of cards played by the opponent will increase as pegging continues, so later states will have more information than earlier states.
There are two things to note about the state space for pegging: first, we don’t need to know any card’s particular history; second, we only need to know about a given card’s rank. Despite these simplifications, it is still challenging to calculate the exact size of the state space. Instead, we will estimate the state space size by calculating lower and upper bounds.
For the lower bound, we can add together the coefficients of \(x^7, x^8,\dots,x^{11}\) from the generating function $$G = (1+x+x^2+x^3+x^4)^{13}$$ to determine that there are \(\approx 2,000,000\) ways to select between 7 and 11 cards from 13 different ranks, while respecting the limit of 4 cards per hand. This underestimates the number of states, however, because it doesn’t distinguish whether a particular card is in the player’s hand.
For the upper bound, we can multiply each of our generating function coefficients by the number of ways to select 2, 3, or 4 cards for the player’s hand. This results in an estimate of \(\approx 400,000,000\) states, but doesn’t account for any double-counting that occurs because cards of the same rank are chosen.
While these bounds provide a broad range for the number of states, they do tell us that we can expect the magnitude of the state space’s size to be between \(10^6\) and \(10^8\). From this we can conclude that any learning agent will have to incorporate some method of state space reduction.
The Pegging Phase’s Actions
The number of actions available to a player on their turn is simply the number of cards remaining in their hand (or lower, if all of the remaining cards would bring the count above 31). Depending on the size of the player’s hand, then, there are between 0 and 4 actions available to the player on any given turn. Of course, decisions only need to be made if there is more than 1 available action.
The Pegging Phase’s Rewards
Points are added to players’ scores as soon as they are earned, so we can directly assign points scored to actions. The opponent’s points can be assigned as negative rewards against the player’s last action.
More holistically, we could also share credit for the point differential between both players across all actions in a given pegging phase, since set-up plays commonly occur (especially for runs) and what you leave in your hand can be as important as what you play down. $$R_{Throwing} = R_{Player} – R_{Opponent}$$
Reinforcement Learning Agents
We have described cribbage as a reinforcement learning problem, with the states, actions, and rewards defined for each phase of the game. But what about the players themselves, the actual learning agents?
Stay tuned for a future post to find out some ideas about how to apply reinforcement learning algorithms to the problem we’ve set out. In the meantime, check out the Python code base that I helped develop for modelling the game of cribbage in reinforcement learning terms.
{kind=link}
{kind=link}
1 Comment. Leave new
Your style of writing is captivating; it feels like having a chat with a pal.