

BLUF: Not all types of unsupervised learning algorithms have the same level of performance in dynamic environments. Algorithms with certain characteristics are more robust to changes in the data being produced.
Today’s continuous streams of data, whether from Point-of-Sale terminals, website traffic, or scientific instruments, are a modern form of Big Data. This means that we are bound to encounter the three Vs: volume, velocity, and volatility. We can tackle the first two characteristics using summarization: a large volume of data can be condensed using an efficient representation that lasts for a longer time than any individual data points. This representation could be clusters, e.g., grouping data points, which can be automatically done with data mining algorithms. These algorithms have many different approaches for how they produce and represent groups.
Determining which algorithm to use is actually a tricky question, because of the nature of the problem: there is no agreed upon ground truth for us to compare our clusters against. In a sense, there are a number of ways we could decide is right for us to cluster data points. For example, we might want to cluster cities by size, since similar-sized cities face similar challenges. Alternatively, we might want to cluster cities by geography. Even here, we must decide: does this mean we want to cluster by continent, by country, or by proximity to bodies of water?
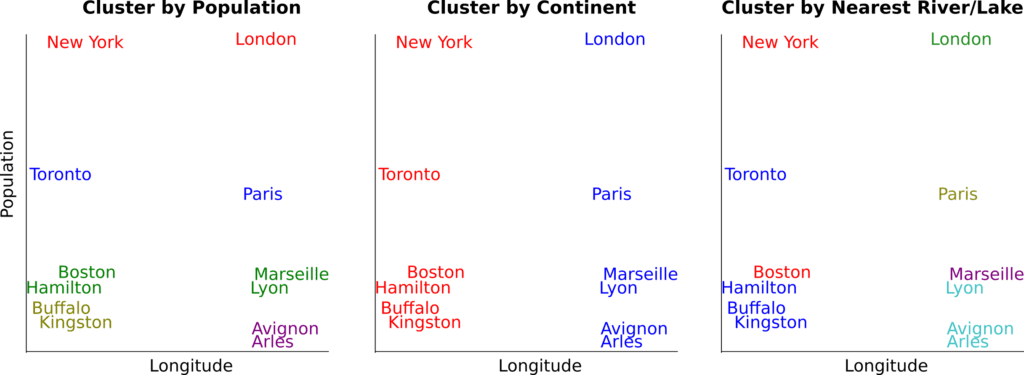
This is an important choice to make, because these data mining algorithms find their way into larger systems: anomaly detectors for security systems or dashboards for corporate decision-making.
But there is an additional challenge with clusters in online environments and it has to do with the third characteristic: what if the nature of our data changes over time? An office tower’s security system will flag different events as being suspicious throughout the day, depending on whether it is the early-morning delivery period, daytime work hours, or overnight. A bar in a university town will want to follow customer trends when students are studying, when summer tourists arrive, and when the town’s inhabitants are left to their own devices. How should we adapt our representation to make sure that our summary remains relevant?
Clustering algorithms for online settings adapt their clusters using a variety of techniques. Some naturally forget the influence of older data points, allowing the clusters to adjust organically over time. Others update a fine-grained representation in real-time and produce a coarser summary on demand. But how well can we expect these algorithms to keep working when the data they are summarizing is changing?
Up until now, there has been no field-wide study that has measured algorithm performance in this kind of dynamic setting. We reported the results of three experiments where algorithms with different characteristics created clusters in simulated environments with different kinds of volatility. We evaluated the algorithms by tracking the evolution of their clusters against the processes that we knew were creating the data and we found the following:
Partition-based vs. density-based clustering algorithms
There are a number of ways for algorithms to create clusters, but two popular ways are: to divide the data space into partitions; and to group data points by how close they are (their density). We found that the first style of clustering algorithm was more robust to changes in the data stream. That might be because partitions are more global, while density-based approaches are vulnerable to local fluctuations for data points.
Types of concept drift
There are a number of different types of concept drift. Some are abrupt and some are gradual. Some alternate between concepts and some progress through the middle ground. We found that large magnitude, short duration concept drifts are the most challenging for data stream clustering algorithms. This is likely because in these situations, the algorithms have difficulty removing the influence of recent data points that are no longer relevant.
Read the whole article here.
{kind=link}
{kind=link}