

This post is based on my experience volunteering with Pathways to Education, a charitable organization with the vision of breaking the cycle of poverty through education. To find out more visit their website at https://www.pathwaystoeducation.ca/
I was volunteering as a tutor with Pathways to Education (P2E) in Kingston during the first year of my PhD when I got an email. P2E was evaluating their program to enhance its service to the community and to ensure its ongoing sustainability. So the P2E Kingston Program Researcher, Ellyn, was looking for someone to help quantitatively evaluate the program’s outcomes. Specifically, she was trying to answer the question “Are P2E’s interventions having the desired effects?”
I came onboard with the evaluation project and learned that P2E Kingston had a lot of data. They had facts and statistics recorded about the students who had been enrolled in the program throughout the years. But these were unorganized and didn’t lend themselves to easy interpretation.
What Ellyn wanted was knowledge. She wanted to know how the program and its interventions had performed in the past. This knowledge would be used to help P2E Kingston decide which interventions should be maintained as well as if and where the program should expand.

I was excited to be able to help out with my expertise, but also cautious (see Weapons of Math Destruction). Real decisions were going to be made on the basis of this evaluation. These stakes clearly called for a principled approach to knowledge discovery. Although a number of frameworks exist to describe how knowledge discovery can and should occur, my experience was of a four-step process: bringing the data together, shaping the data for analysis, mining the data of knowledge, and presenting that knowledge to stakeholders.
Bring The Data Together
The first part of knowledge discovery involves unglamorous grunt work: the data has to be brought together. P2E’s data had been collected and collated by different offices on a yearly basis, without an overarching data management plan. This meant that one team might have student demographic records, while another team maintained tutorial attendance records. Working hand-in-hand with Ellyn was key here: she knew who “owned” what data in the organization and she gathered CSV and Excel files with data for student demographics, school attendance, participation in mentoring and tutoring, credit accumulation, academic outcomes, and post high school status.
This got all of the data into one folder, but to simplify analysis I wanted to get everything into one clean file. I definitely didn’t want to do it by hand: not only would that burn through time, it’s a brittle process that would need to be repeated anytime new records or data was found. So I invested the time in writing some custom code that would combine an arbitrary number of CSV files into one CSV file based on the ubiquitous Student ID number (see Github project)
Once that was done, we were able to look at the records of 866 students who had been registered with P2E since the program had established a Kingston location in 2015.
Shape the Data for Analysis
Unfortunately, not all of the student records were complete. Some records were missing demographic information. Other students had not been involved with P2E long enough to become attributed, meaning that they’d accumulated school credits for 2 years with the program. Ellyn was clear that this was an important distinction, since P2E’s performance was regularly assessed internally and externally with respect to attributed students. In order to be consistent with P2E’s other reporting, we would need to consider only attributed students. After cleaning the record set to remove students with insufficient data, who weren’t working towards high school graduation, or who had less than 2 years of records, we ended up with 321 records.
Talking with Ellyn, we also came up with some ways to improve the data set. First, we normalized all the records from Calendar Year to High School Year (i.e., 2014 to Grade 9/Yr 1). This was really helpful, since P2E was much more interested in students’ progress through high school than the program’s own progress through time. Second, we added variables to the data set, such as “Total Tutoring Sessions Attended” and “Total Days Missed,” which summed year-by-year statistics.
We finished the data cleaning process by merging and editing fields such as School Board affiliation to ensure consistency. We filled in missing values for voluntary response fields such as “Indigenous status” as “No Response.” We wanted to remove edge cases in the data and reduce the number of ways that a single idea was referenced within the data set. Throughout the cleaning process, we would sometimes realize that we had gaps in the data set. Ellyn would go out to find the missing data and then we’d bring it all together again.
Mine the Data for Analysis
With the data brought together into one file and cleaned for analysis, we were finally ready to begin statistical analysis and data mining. This is the sexy part of the process that everyone talks about: using math to describe relationships between data points and draw conclusions. For all that, this was also the part of the process that we spent the least amount of effort on: I’d estimate that only 10% of our time was spent here.
On a large scale, this kind of data analysis is done by Netflix and Amazon all the time to understand their customers and how they spend money. They want to know what show you’ll binge next and which additional items you’d buy based on the ones in your cart.
For this evaluation project, we wanted to know if P2E’s interventions were having a positive effect on the students enrolled in the program. Concretely, did the P2E program help students to graduate on time?
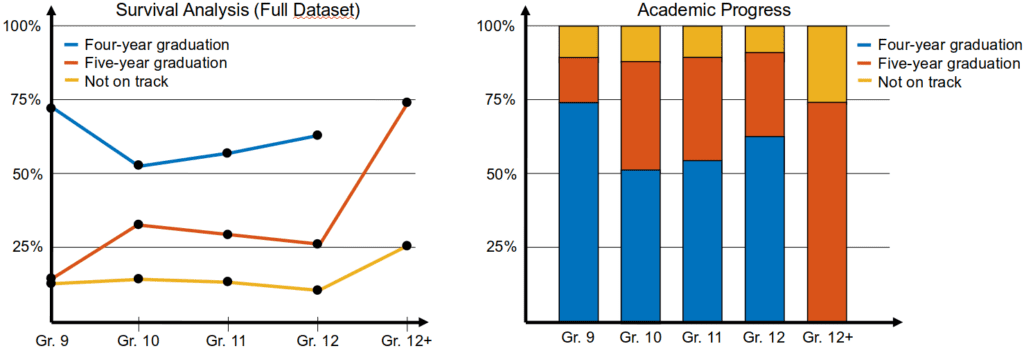
Graduation is an all-or-nothing measure that happens at the end of high school. As a stand-in, we used yearly credit accumulation as a proxy for academic success. Not only did individual credits allow us to measure success on a finer time scale, but it also allowed us to compare students’ trajectories with provincial guidelines for being on-track to graduate in four or five years. This became the central point of our knowledge discovery: how did P2E students accumulate credits? Was there a difference by school board? Did boys and girls accumulate credits differently?
Importantly, sometimes Ellyn and I realized that we couldn’t easily answer a question with the data we had. This sent us back to either bringing more data together, or to re-shaping the data so that we could ask our questions.
Present the Knowledge to Stakeholders
The analysis and mining was now done and I had sent Ellyn all of the pretty graphs that I’d produced. Were we done? Definitely not! The whole point of this exercise was for something to happen. Specifically, P2E wanted to decide two things: which program interventions were helping students in Kingston; and how should they expand the program?
Ellyn’s experience was crucial here: she knew the external stakeholders and she knew how these results would fit into everything else that the stakeholders were considering. She gave me some excellent feedback on those pretty graphs that I’d produced, including:
– Some of the terminology needed to be changed. For example, the technical term survival analysis was correctly judged to be inappropriate. We went with academic progress instead. Not only is this a more positive, humanizing title, it also connects with the goal of the research: determining if P2E’s interventions were improving students’ academic progress.
– Some of the visualizations needed to be changed (i.e., lines to stacked bar chart). A good clue for this was if Ellyn couldn’t immediately understand the graph as the project lead, then none of the stakeholders would know what we were talking about.
As well, results from other parts of the project would occasionally suggest new questions, so we would go back to mining the data to answer it.
Overall, I learned a lot from being a part of this nearly year-long project. Although my master’s had provided me with a lot of theoretical knowledge, it was eye-opening to see just how little time we spent data mining. Instead, we spent our time wrangling data so it could be analysed and then wrangling those pretty graphs so that they could be understood.
A few other key lessons that I learned:
- Knowledge discovery is an iterative process. Later stages often send you back to early stages. Although it’s tempting to think about knowledge discovery as a conveyor belt, it’s actually a machine that you’re constantly building up and tinkering with.
- Knowledge discovery needs domain expert input. It’s easy to pay lip-service to this idea, but there is no way the project would have been successful without Ellyn. Without her efforts at every stage, I would have spun my wheels to produce analysis that would end up collecting dust.
- Knowledge discovery ends with action. Thanks to Ellyn’s knowledge and effort, our analysis helped to answer the question that we had started out by asking: “Are P2E’s interventions having the desired effects?” This is sets the stage for the last step in the knowledge discovery marathon: taking action
Data Analytics Marathon: Why Your Organization Must Focus on the Finish
With all that, if you take away one message from this, I hope it is that knowledge discovery can be used for good in your community today. Whether you are a non-profit organization, community member, or data analyst, keeping the whole knowledge discovery process in mind will help you to have an impact.
{kind=link}
{kind=link}